Why evaluating LLM apps matters and how to get started
Large Language Models (LLMs) are all the hype, and lots of people are incorporating them into their applications. Chatbots that answer questions over relational databases, assistants that help programmers write code more efficiently, and copilots that take actions on your behalf are some examples. The powerful capabilities of LLMs allow you to start projects with rapid initial success. Nevertheless, as you transition from a prototype towards a mature LLM app, a robust evaluation framework becomes essential. Such an evaluation framework helps your LLM app reach optimal performance and ensures consistent and reliable results. In this blog post, we will cover:
- The difference between evaluating an LLM vs. an LLM-based application
- The importance of LLM app evaluation
- The challenges of LLM app evaluation
- Getting started
- Collecting data and building a test set
- Measuring performance
- The LLM app evaluation framework
Using the fictional example of FirstAidMatey, a first-aid assistant for pirates, we will navigate through the seas of evaluation techniques, challenges, and strategies. We’ll wrap up with the key takeaways and insights. So, let’s set sail on this enlightening journey!
Evaluating an LLM vs. an LLM-based application
The evaluation of individual Large Language Models (LLMs) like OpenAI’s GPT-4, Google’s PaLM 2 and Anthropic’s Claude is typically done with benchmark tests like MMLU. In this blog post, however, we’re interested in evaluating LLM-based applications. These are applications that are powered by an LLM and contain other components like an orchestration framework that manages a sequence of LLM calls. Often Retrieval Augmented Generation (RAG) is used to provide context to the LLM and avoid hallucinations. In short, RAG requires the context documents to be embedded into a vector store from which the relevant snippets can be retrieved and shared with the LLM. In contrast to an LLM, an LLM-based application (or LLM app) is built to execute one or more specific tasks really well. Finding the right setup often involves some experimentation and iterative improvement. RAG, for example, can be implemented in many different ways. An evaluation framework as discussed in this blog post can help you find the best setup for your use case.
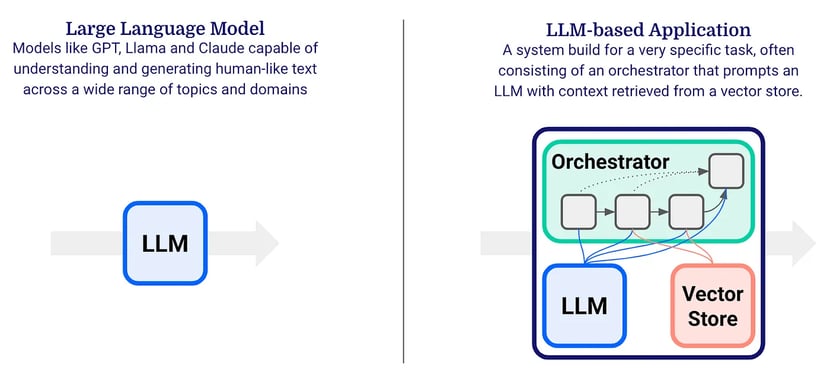
An LLM becomes even more powerful when being used in the context of an LLM-based application.
FirstAidMatey is an LLM-based application that helps pirates with questions like “Me hand got caught in the ropes and it’s now swollen, what should I do, mate?”. In its simplest form, the Orchestrator consists of a single prompt that feeds the user question to the LLM and asks it to provide helpful answers. It can also instruct the LLM to answer in Pirate Lingo for optimal understanding. As an extension, a vector store with embedded first-aid documentation could be added. Based on the user question, the relevant documentation can be retrieved and included in the prompt, so that the LLM can provide more accurate answers.
Importance of LLM app evaluation
Before we get into the how let's look at why you should set up a system to evaluate your LLM-based application. The main goals are threefold:
- Consistency: Ensure stable and reliable LLM app outputs across all scenarios and discover regressions when they occur. For example, when you improve your LLM app performance on a specific scenario, you want to be warned in case you compromise the performance on another scenario. When using proprietary models like OpenAI’s GPT-4, you are also subject to their update schedule. As new versions get released, your current version might be deprecated over time. Research shows that switching to a newer GPT version isn’t always for the better. Thus, it’s important to be able to assess how this new version affects the performance of your LLM app.
- Insights: Understand where the LLM app performs well and where there is room for improvement.
- Benchmarking: Establish performance standards for the LLM app, measure the effect of experiments and release new versions confidently.
As a result, you will achieve the following outcomes:
- Gain user trust and satisfaction because your LLM app will perform consistently.
- Increase stakeholder confidence because you can show how well the LLM app is performing and how new versions improve upon older ones.
- Boost your competitive advantage as you can quickly iterate, make improvements and confidently deploy new versions.
Challenges of LLM app evaluation
Having read the above benefits, it's clear why adopting an LLM-based application can be advantageous. But before we can do so, we must solve the following two main challenges:
- Lack of labelled data: Unlike traditional machine learning applications, LLM-based ones don’t need labelled data to get started. LLMs can do many tasks (like text classification, summarization, generation and more) out of the box, without having to show specific examples. This is great because we don't have to wait for data and labels, but on the other hand, it also means we don't have data to check how well the application is performing.
- Multiple valid answers: In an LLM app, the same input can often have more than one right answer. For instance, a chatbot might provide various responses with similar meanings, or code might be generated with identical functionality but different structures.
To address these challenges, we must define the appropriate data and metrics. We’ll do that in the next section.
Getting started
Collecting data and building a test set
For evaluating an LLM-based application, we use a test set consisting of test cases, each with specific inputs and targets. What these contain depends on the application's purpose. For example, a code generation application expects verbal instructions as input and outputs code in return. During evaluation, the inputs will be provided to the LLM app and the generated output can be compared to the reference target. Here are a few test cases for FirstAidMatey:

Some test cases for our first-aid chatbot application
In this example, every test case contains a question as input and a correct reference answer as target. In addition to this, historical responses, and even historical user feedback could be added to the test case. This allows you to check whether newer answers improve upon older ones and whether user feedback is being addressed. Ideally, your test set consists of verified reference answers, but if you quickly want to compare a new model to an older one, using the historical responses and feedback is an option.
As you typically start the development of an LLM-based application without a dataset, it is important to start building the test set early. You can do that iteratively by adding those examples on which the current model fails. Initially, it will be the developers who will experiment the most with the LLM app and it’s them who will add the first test cases based on their manual tests. Nevertheless, it is important to involve the business or end users soon in the process as they will have a better understanding of the relevant test cases. To kickstart the test set, you can also use an LLM to generate input-target pairs based on, for example, your knowledge base. Over time, the test set should cover the entire spectrum of topics that matter most to the end users. Therefore, it is important to keep collecting user feedback and adding test cases for the underperforming and underrepresented topics.
Measuring evaluation performance
Given the set of test cases, we can now pass the inputs to the LLM app and compare the generated responses with the targets. Because there is not one single correct answer for each input, we cannot literally compare the response with the reference answer. The response may be worded differently while having the same meaning as the reference. What we can do though, is to evaluate several properties of the response, as a proxy for the response quality. The relevant properties to test for depend on the application and available data. Here is a list of properties of the FirstAidMatey responses, and how they can be turned into a metric:
- Factual Consistency: Use an LLM to assess whether the generated answer is factually consistent with the reference answer.
- Pirateness: Use an LLM to evaluate whether the answer is written in Pirate Lingo.
- Semantic Similarity: Compute the cosine similarity between the embeddings of the generated and reference answers. Note that this is much cheaper to compute than Factual Consistency, but might not be as correlated with correct answers.
- Verbosity: Divide the length of the generated answer by the length of the reference answer. The higher the verbosity, the more chatty the LLM app is behaving, which might not be the app's intention.
- Latency: Measure the time it takes the LLM app to generate the response. This allows you to make the tradeoff between more accurate, but slower configurations.
Depending on the use case, you could have more/different properties. For example, for a code generation LLM app, one additional property could be the Syntactically Correctness of the generated code which could be measured by sending the code through a compiler. The image below illustrates how a property can be evaluated by using an LLM.
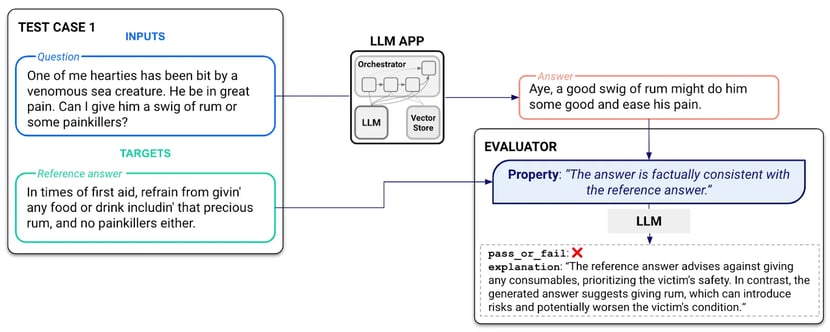
An illustration of the Factual Consistency metric being evaluated via another LLM call.
Once all properties have been evaluated for all tests, the average score for each metric can be computed and compared with the baseline/target performance. When you’re experimenting with different configurations, e.g. for RAG, the test scores point you towards the most favourable candidate. The tradeoffs between correctness, verbosity and latency become clear as well. In addition to the metric scores, the failure cases can provide useful insights for further improvement. Have a closer look at some of the failed tests, they might provide useful insights for improving your LLM app further.
You might wonder, “If the LLM can't get the answer right, how can we trust it to evaluate that same answer? Wouldn't there be a bias toward its own output?” Indeed, that sounds counterintuitive, but the main idea here is that evaluation is easier than generation. Consider the analogy of creating versus evaluating a painting. When creating a painting you’d need to simultaneously take multiple properties like composition, colour, perspective, light and shadow, texture, intended message, … into account. Evaluating a painting on the other hand allows you to focus on one property at a time; it's simpler to judge a finished piece than to make one from scratch. The same idea applies to LLMs: while generating a proper response can be challenging, critically evaluating an existing one is more straightforward. The evaluation becomes even more feasible if a reference response is available, like for the Factual Consistency property.
The LLM app evaluation framework
Let’s tie everything together in this final section. The image below shows an overview of the evaluation framework and illustrates an important feedback loop:
- The LLM app, properties and test cases are passed to the Evaluator which loops over all test cases and passes the test inputs through the LLM app. The resulting outputs are then evaluated by looping over the properties and collecting the results as metrics.
- The evaluation results are stored for further analysis. In addition to the metrics, it is also important to track the configuration of the LLM app (i.e. the used LLM and parameters, the used RAG components and parameters, system prompts, etc.) so that you can easily distinguish the most promising experiments and gain insights for improving the app further. You could store the evaluation results and LLM app configuration in your own database, or use tools like MLflow which gives you immediate access to a user-friendly interface.
- Once you’re happy with the performance, you can release the new version of your application, either to internal or external users.
- In the early phases of the project, it’ll be the developers who are testing and collecting feedback. Later on, feedback can be collected from the end users, either directly (thumbs up/down, and written feedback) or implicitly (conversational turns, session length, accepted code suggestions, etc.).
- Extend the test set by analysing the incoming feedback and adding test cases for the situations that are underrepresented and not handled well by the current model.
- Spot trends in the incoming feedback and turn them into LLM app improvements. Depending on the situation, you can improve the orchestrator, (e.g. create a chain of separate LLM calls instead of a single prompt), the retrieval process (e.g. improve the embeddings) or the LLM (e.g. change the model, the parameters or even consider fine-tuning).
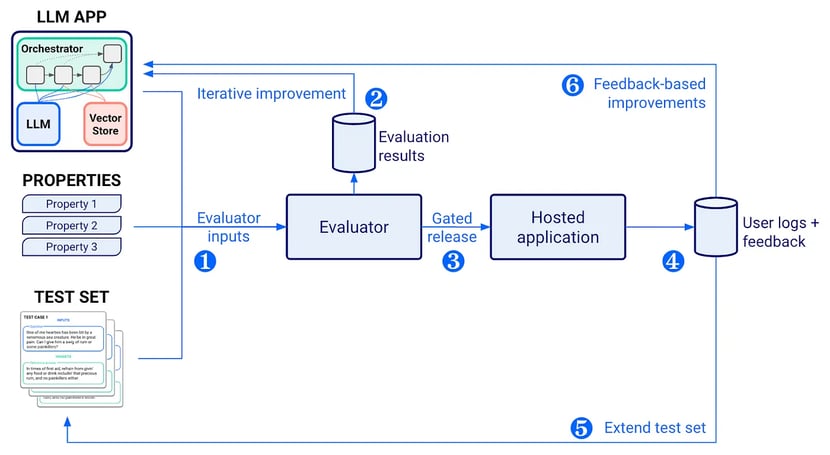
Overview of the evaluation framework for LLM-based applications.
For an illustration of steps 1 and 2, have a look at the following Jupyter notebook. This notebook illustrates the concepts explained in this blog post. You can see how properties, test cases and LLM app versions can be defined and sent to the Evaluator. In addition to printing the evaluation results, they are also logged into an MLflow dashboard for further analysis. Definitely check it out, it will make the discussed topics even more concrete.
Conclusion
Evaluating an LLM-based application is an essential part of LLM app development. The evaluation framework presented in this blog post eases comparing experiments during development, ensures consistent performance and provides insights for further improvements.
The lack of labelled data, i.e. the first challenge we encountered, can be solved by building a test set early on and iteratively expanding it by adding the hard and underrepresented cases. The second challenge, the fact that there are often multiple correct answers, can be overcome by looking at different properties of the generated outputs. Some of these properties can be measured with simple formulas or rules, while others can be evaluated with an LLM.
Finally, we discovered a crucial feedback loop where evaluation results and collected user feedback drive the LLM app performance forward. In conclusion, systematic evaluation is the compass that steers your LLM app towards success!

