As excitement has grown around Machine Learning, more and more companies are attempting to leverage ML. However, many projects are languishing and not returning the promised results. MLOps attempts to solve many of the issues plaguing these projects and finally allows ML to deliver the benefits it promises. We at Radix are in the unique position to have implemented ML projects successfully across many industries and use cases. In the past, we’ve written about MLOps and its principles at a high level, for example, in our recent post on moving from DevOps to MLOPs. In this series of blog posts, we aim instead to give you an in-depth look at what some concrete implementations of MLOps look like in the form of various “MLOps Stacks”, each tailored to a specific use case. In part 1 of our series, we discussed how to serve and scale multiple Computer Vision models for a mobile app. In part 2, we covered live predictions of Key Business Metrics. These articles aim to go into the technical details around each stack and are aimed at Machine Learning Engineers.
Recommender Systems
In this part 3, we are going to discuss Recommender systems. Recommender systems give relevant content suggestions based on users’ profile info and how they interact with the available content. They can suffer from performance loss over time though, because the information from the past quickly becomes less relevant to predict what good content suggestions will be in the future. It’s necessary to regularly retrain the recommender system with the newest information to remedy this. In this particular case, we’ll retrain by incorporating the latest user behaviour.
Key Challenges
Many fundamentals need to be covered by an MLOps stack, but the following are the ones that we found to be especially important in this use case.
- High availability - An update of the recommendation system cannot cause downtime in the recommendation service. The old model is phased out incrementally while the updated model is phased in. This is known as a hot swap.
- High throughput and low latency - Users should get the best possible recommendations as fast as possible. Additionally, the system can handle high traffic without impacting performance.
- Monitoring - Model performance is continuously monitored to check for drops in the quality of the content recommendations and take action. When the valuable data input stream is down, an alarm goes off to keep the amount of lost data to a minimum.
This stack was designed for a client with many infrastructures deployed in AWS, so it was only natural that we build on this and use many AWS tools. Most of the AWS-specific services we use here could easily be replaced by services from any other cloud provider.
Architecture
An MLOps Stack should support the full life cycle of a machine learning model. To structure this, we’ve split the life cycle into four different steps:
- Data Acquisition - The first step in developing any model involves acquiring data to train your model on. The primary driver of model performance is the quality of the data it is trained on, so getting this right is very important.
- Model Training - Once you have data, the next step is to train your model on this data. Often you’re not sure which model to use, so being able to experiment rapidly requires this step to facilitate that. Further, since this is where your model is created, it’s important to ensure that everything you do here is reproducible.
- Deployment and Packaging - Once you have a trained model, package it and deploy it to your serving infrastructure. How you package your model will determine how other services will interact with it. Being able to deploy new models quickly and in an automated way allows you to quickly update models in production and always provide the best models possible to your users.
- Model Serving and Monitoring - Finally, once you have a deployable model artifact you need to set up infrastructure to serve it to your users and to monitor it. Monitoring your model is important as it allows you to ensure that it is performing as expected.
Data Acquisition
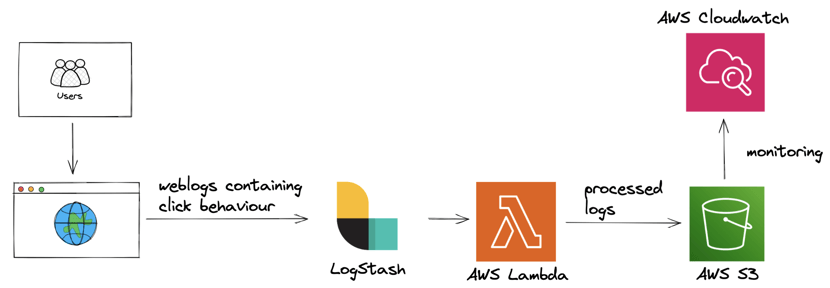
Users generate weblogs when interacting with web page content. These weblogs are captured using Logstash and streamed in real-time to AWS Lamba: a processing function that applies business logic to the weblog events. Processed weblogs are stored in an S3 data lake for later consumption.
A Cloudwatch alarm is set up to go off when we no longer receive weblogs. An email notification is sent to the on-duty engineer when the alarm is triggered.
Pros
- Serverless and automatically scaled compute using AWS Lambda
- Cheap, versatile storage using AWS S3
- Collect user feedback to train model
Training
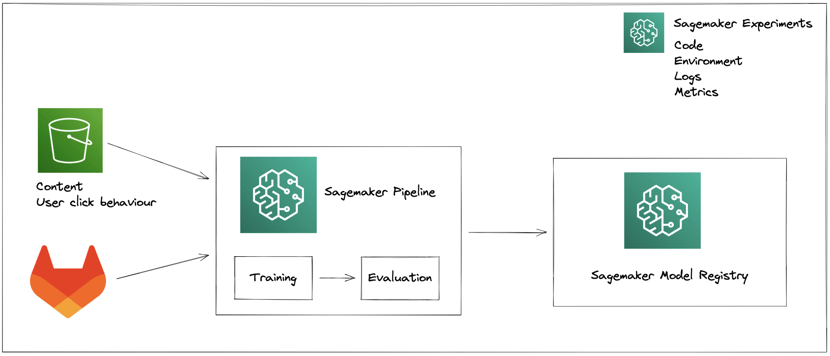 An AWS Sagemaker Experiment is manually started. Our S3 data lake contains user click behaviour and possible recommendation content. We use Gitlab to version our training code. The training is evaluated against a custom evaluation script that aims to maximize user clicks on the recommendations that we give. Once training has been completed, the model is stored in a Model Registry. Sagemaker Experiments allow us to version the entire experiment from start to finish, including code, input data, artifacts, logs and metrics.
An AWS Sagemaker Experiment is manually started. Our S3 data lake contains user click behaviour and possible recommendation content. We use Gitlab to version our training code. The training is evaluated against a custom evaluation script that aims to maximize user clicks on the recommendations that we give. Once training has been completed, the model is stored in a Model Registry. Sagemaker Experiments allow us to version the entire experiment from start to finish, including code, input data, artifacts, logs and metrics.
Pros
- Easily track, evaluate and compare machine learning experiments using AWS Sagemaker Experiments
- Access to powerful GPUs with AWS Sagemaker
- Experiments are fully reproducible
Deployment and Packaging
 We deploy a new recommendation model when the model evaluation metrics from the Sagemaker Experiment are better. The new model is pulled from the Model Registry and packaged using FastAPI and Docker. Afterwards, it is sent to an AWS Elastic Container Registry (ECR) from which it can be incorporated into the serving architecture.
We deploy a new recommendation model when the model evaluation metrics from the Sagemaker Experiment are better. The new model is pulled from the Model Registry and packaged using FastAPI and Docker. Afterwards, it is sent to an AWS Elastic Container Registry (ECR) from which it can be incorporated into the serving architecture.
Pros
- Thorough model testing before final release using Dev and Prod deployments
- Easily manage Dockerized applications in an ECR
Serving and Monitoring
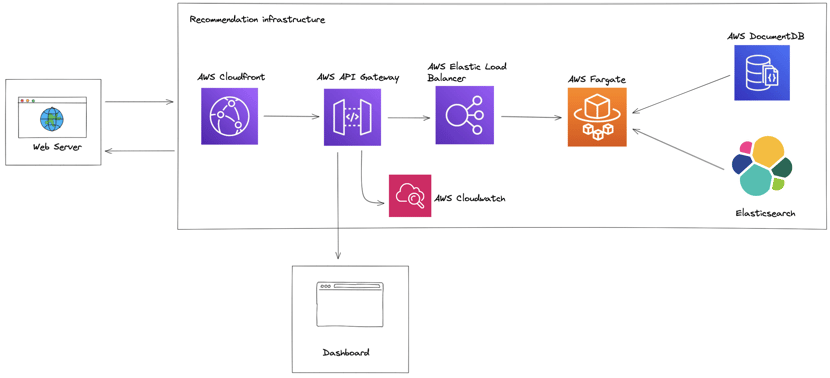
Cloudfront receives the requests and forwards them to API Gateway. Requests get throttled based on requests/second (RPS). The Elastic Load Balancer (ELB) directs calls to multiple APIs running in Fargate. The API container mentioned in the previous section is deployed here and automatically scales based on the CPU usage of the container instances.
The recommendation model uses the user and content information stored in DocumentDB. ElasticSearch is used as a first broad selection of possible content to limit the inference workload for the model. The recommendation model then ranks these candidates, so we’re able to return the top K recommendations.
The entire infrastructure is deployed using Terraform. In the case of redeployment, the old API containers are phased out, while the new ones are phased in. This is known as a hot swap and ensures the service stays available at full capacity during redeployment.
Service health is monitored using a custom dashboard. The dashboard gives information about the number of calls, response time, and error count, which is gathered from API Gateway. Cloudwatch alarms are set up to notify when the service health goes below the desired threshold.
Pros
- Automatic scaling, deployment and container management with AWS Fargate
- Fetch first set of candidates quickly using Elasticsearch
- Automatic service health monitoring using AWS Cloudwatch
- Automatic authorization and access control in API Gateway
- Highly durable, high throughput storage in DocumentDB
The Next Level
As with all projects, there are always new features to add. Here are the ones we’d look at next for this use case.
- Automatically retrain the recommendation system - Training is triggered manually at the moment. Ideally, retraining is triggered automatically using user feedback based on click behaviour. If a drop in user engagement is detected, retraining is triggered
- Automatically deploy model improvements - Deploying a better model is done manually for the most part. Ideally, a better model is deployed automatically after training
Conclusion
Want to learn more about MLOps? Check out our other articles:
- MLOps: Machine Learning Ops and why your business should practice it
- 4 Must-Do’s When Starting Your MLOps Journey
- The Consequences of NOT Applying MLOps to Your AI Projects
- From DevOps to MLOps: shared principles, different practices
- MLOps tech stack part 1: serve & scale multiple Computer Vision models for a mobile app
- MLOps tech stack part 2: Live Predictions of Key Business Metrics
Excited to work with us on MLOps? Apply to our MLOps Engineer Vacancy here.

