Techniques and Architectures for Remote Sensing and Agricultural Applications
Join us in this two-part blog series as we, Ruben Broekx, Team Lead and Solution Architect at Radix, and Mattia Molon, Machine Learning engineer at Radix, collaborate with domain experts from VITO Remote Sensing to create a pixel-based crop classification model. We’ll guide you through the challenges and discoveries that shaped our understanding of agricultural and Remote Sensing applications while benefiting from the invaluable insights provided by our partners. It’s going to get technical, so be prepared. Let's learn and grow together!
Unlocking the Potential of Pixel-Based Crop Classification for a Sustainable Future
Crop classification is a vital process in the agriculture and food industry, enabling us to identify and categorize various types of crops on a larger scale. Accurate insights into crop type distributions are essential for supporting the European Union's Common Agricultural Policy (CAP) and promoting sustainable practices. Remote Sensing allows us to monitor the dynamic nature of growing seasons, meteorological conditions, and agricultural practices over time, enabling us to make accurate predictions.
However, generating these crop type distributions has its challenges. It’s not trivial to orchestrate a joint effort on crop type mapping across different countries due to variations in data accessibility and inconsistencies in labeling systems. While some countries provide open access to parcel data, others still need to catch up in sharing such information. This disparity and each country's unique labeling approach complicate data harmonization across the continent.
In this two-part blog series, we dive deep into the creation of a pixel-based crop classification algorithm. This first part explores the rationale behind pixel-based approaches and the benefits of applying time series analysis to multispectral data. We'll also discuss how, through fast iteration, we end up with a good model architecture for pixel-based crop classification. In the second part, we’ll push the limits of the best-performing model, adopting best practices like data augmentation and exploring advanced Machine Learning techniques to optimize the training process.
Unraveling Pixel-Based Crop Classification: Key Components and Considerations
The goal of crop classification is to map various crop types in a specified area accurately. Knowing the crop types and their distribution helps make informed resource allocation decisions, monitor crop health, predict yields, and drive sustainable agricultural practices. Remote Sensing plays a significant role in crop classification. Satellite imagery and related data sources offer unparalleled spatial and temporal coverage, making them invaluable for monitoring large agricultural areas. These data sources can extract essential features for crop classification, such as spectral reflectance, vegetation indices, and radar information.
A single pixel’s observation over time captures crucial information on the crop located at that pixel, such as the evolution of its growth, its health, when harvesting takes place, and others. Analyzing individual pixels in Remote Sensing images over time allows us to identify the different crops’ unique multispectral and textural signatures, leading to successful classification. There are several reasons to go for a pixel-based approach:
- Performing pixel classification simplifies crop classification since it reduces it to a time series problem. Multiple solutions already exist for this, allowing us to iterate solutions faster.
- The temporal evolution of one pixel's multispectral and textural information throughout a growing season conveys most of the information needed for the classification process, such as growth stages and phenological events.
- Pixel-based approaches require less data storage, compute, and post-processing than image-based methods, leading to more manageable data pipelines and faster processing times.
- Pixel-based classification allows for lighter inference by enabling the sampling of specific fields instead of predicting entire areas, reducing computational resources and more targeted decision-making.
While pixel-based classification offers many advantages, it's important to acknowledge that it may not be perfect in every scenario. Integrating geospatial information on top of the temporally extracted features could provide additional context and improve detection for mixed crop types, like trees interspersed with grass. Nevertheless, pixel-based classification remains a powerful and effective approach to address crop classification challenges like the one addressed in this blog series.
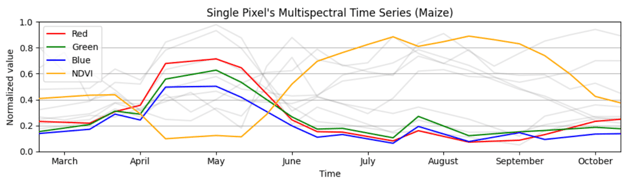
For this project, we collected training data by harmonizing high-quality reference datasets such as several multi-year Land Parcel Identification System (LPIS) datasets over several countries. The data is cleaned before feeding it into the model using expert knowledge and best practices like cloud and shadow removal, temporal resampling, and additional filtering like assuring the pixels are sampled from the cores of the fields. A single pixel comprises information from various bands, such as RGB, Normalized Difference Indices like NDVI, Synthetic Aperture Radar (SAR) data, and temperature information. The image below shows all the information in one Maize pixel. Only RGB and NDVI information is highlighted for readability.
Rapid Iteration: Finding the Right Model Architecture
A good start in developing a suitable solution is to test the waters first through rapid iterations over various model architectures. By quickly testing and evaluating different models, we aim to narrow down the most effective solution while also gaining insights into the strengths and weaknesses of each approach and the difficulties found in the problem.
We start this section with out-of-the-box solutions and gradually move to more advanced architectures. We'll discuss the performance and suitability of each model for handling the complexities of our data. In Part 2 of this blog series, we will leverage the insights gained from this iterative journey to refine and optimize our chosen model, paving the way for even better performance.
First Steps to a Working Solution
It’s always a good idea to first see what’s already out there. Using open-source packages and models, we quickly create a simple model to investigate the difficulty of the problem at hand, find any problems with the provided data, gather valuable insights into the use case, and set a good baseline performance.
Starting small and gradually building further is part of a structured approach to creating projects with impact within Radix. For every project, we apply the following four guidelines:
- Measure and maximize the impact: deliver models that provide tangible benefits and improvements.
- Understand the end-user: by understanding their needs and expectations, we tailor our models to address their specific challenges and pain points.
- A working solution from the start: create a fully functional solution that allows us to receive feedback at an early stage to better tailor the solution to the end-user’s needs.
- Fast iteration through agile development: quickly adapt and evolve our solution in response to new insights and changing requirements.
Before developing custom solutions to this problem, we looked at three different out-of-the-box models to create a strong baseline. These models have proven effective in similar applications while balancing simplicity and performance. Hence, they are an excellent starting point for the problem at hand. The models in question are:
- A model from the `sktime` library, which supports modeling functionality for time series analysis. More specifically, we used a K-nearest neighbor time series classifier.
- A second model extracts statistics from the time series using the `tsfresh` package and fits a simple random forest model on these features.
- The last model we tested is `lightGBM`, a gradient-boosting framework that uses tree-based learning algorithms to make predictions.
To evaluate the models' performance, including those we introduce later, we mainly focus on the F1-score. The metric to optimize is the macro F1-score since it treats each class equally, independent of the number of samples it contains in our dataset. The figure below shows the per-class F1-score and the macro F1-score via the dotted horizontal line.
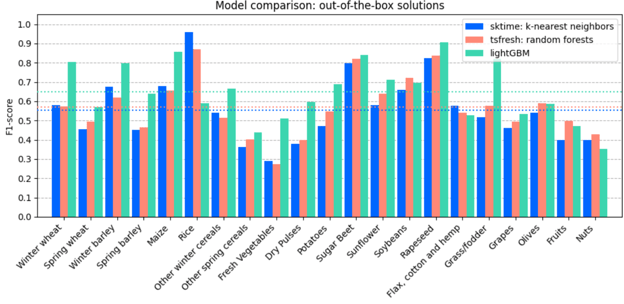
Based on these findings, we decided to use lightGBM as our baseline model since it has the best overall performance. Another interesting observation is that the classes differ heavily in performance, hinting that some classes are more challenging to predict than others. Some difficult classes are grapes, olives, fruits, and nuts. This is because they grow on trees, which are usually surrounded by other crops such as grass, and thus contain a lot of noise in their signal and their target label. Opting for a model that is not only pixel-based but also takes spatial information into account will likely increase the performance of these classes.
Exploring Advanced Model Architectures
Once we established a solid baseline using out-of-the-box models, it became evident that there was room for improvement in our pixel-based crop classification system. The need for more advanced models arises from the increasing complexity of the problem and the potential for higher accuracy and better generalization. Our next step was to explore advanced model architectures to further enhance performance. This section will delve into the custom Deep Learning models we developed, including Long Short-Term Memory networks (LSTM), one-dimensional Convolutional Neural Networks (CNN), and Transformer models. We'll also discuss how the evaluation results compare to our best-performing baseline model, LightGBM.
To address the limitations of the baseline models and better capture the complex temporal patterns within Remote Sensing data, we decided to experiment with the following advanced model architectures:
- Long Short-Term Memory networks (LSTM) are a type of recurrent neural network (RNN) that can model temporal dependencies present in sequential data, such as multi-temporal Remote Sensing images. We developed an LSTM-based model to capture the temporal dynamics of the agricultural growth cycle and better distinguish between different crop types.
- Convolutional Neural Networks (CNN) are known for effectively capturing image proximity patterns. However, they also show their use in utilizing the temporal patterns found in time series, making them a natural choice for Remote Sensing applications. We designed a custom CNN architecture tailored to our specific problem, focusing on optimizing feature extraction and reducing overfitting.
- Transformer models come from the natural language processing field but have shown to be remarkably performant in various other tasks, including sequence modeling. Given their ability to capture temporal dependencies over a wider input range via their attention mechanism, we explored Transformers as a potential solution for our crop classification problem.
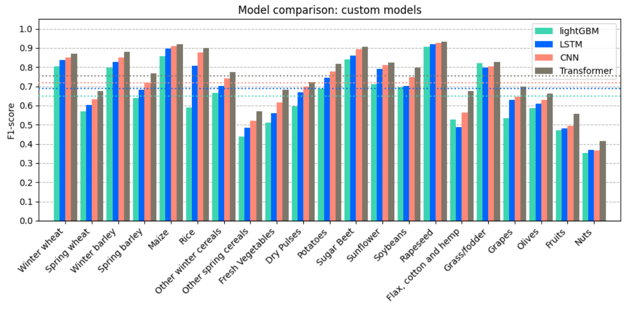
To assess the performance of our custom Deep Learning models, we used the same evaluation metrics and methodology as with the baseline models. This allowed for a fair comparison and enabled us to determine every approach's strengths and weaknesses. As the figure below shows, all three custom models improve over the baseline model, where the Transformer model comes out on top. Not only does the Transformer perform better on average, but it also has the best predictive performance for each and every individual crop type class.
 Moving forward, we focus on further refining and optimizing the Transformer model to maximize its performance and ensure it can be applied in practice. This is done by introducing best Machine Learning practices like data augmentation, learning rate and optimizer tuning, applying changes to the transformer architecture, and others. This model will end up predicting which crops have been planted where in Europe on a yearly basis.
Moving forward, we focus on further refining and optimizing the Transformer model to maximize its performance and ensure it can be applied in practice. This is done by introducing best Machine Learning practices like data augmentation, learning rate and optimizer tuning, applying changes to the transformer architecture, and others. This model will end up predicting which crops have been planted where in Europe on a yearly basis.
Embracing the Power of Transformers for a Sustainable Future in Remote Sensing Applications
In this first part of our blog series, we explored various techniques and architectures in the quest for the most effective solution for pixel-based crop classification. Our journey began with establishing a solid baseline using out-of-the-box models, where LightGBM emerged as the best performer. From there, we compared this baseline against advanced Deep Learning architectures, like custom CNN, LSTM, and Transformer models.
After building, training, and evaluating the custom models, the Transformer model had the best predictive performance. This underscores the power and versatility of Transformer models, which have already demonstrated remarkable success in natural language processing and are now proving their worth in Remote Sensing applications.
In the next part of this blog series, we continue improving the model’s performance, specifically that of the Transformer. Here, we will dive deeper into the challenges and strategies for further refining the Transformer model. We will discuss advanced Machine Learning techniques, data processing methods, and ways to overcome the inherent noise present in Remote Sensing data to push the boundaries of pixel-level crop classification.
Please follow us along this journey where we’ll bridge the gap between Remote Sensing and agricultural applications, ultimately contributing to a more sustainable and efficient global food system.

