Forecasting is all about predicting the future based on historical patterns. For instance, in retail, forecasting may involve predicting sales for a specific product. Some other applications are revenue estimates, predicting public transport load, energy usage forecasting, demand planning, etc. Accurate forecasts are crucial as they enable companies to make informed decisions, ultimately leading to improved operational efficiency and profitability.
Traditionally, forecasting is done using statistical methods or with a particular type of machine learning model called trees. The applicability of deep learning, the subset of machine learning on which foundation models are based, has divided the forecasting community. Some say they do provide a benefit in cases when a lot of data is available, others argue in favour of simplicity of traditional methods and report only marginal gains of deep learning. On the contrary, in natural language processing (NLP) and computer vision (CV), deep learning has clearly outperformed the traditional methods already quite a while ago and foundation models are an established phenomenon.
Recently, foundation models for forecasting have started to pop up. Since the authors of these models claim promising results, we will battle-test three of the latest forecasting foundation models ourselves in this blog post. The first one is closed-source from the company Nixtla, called TimeGPT, currently in closed beta. The other two are open-source. One is called Lag-Llama, taking inspiration from the NLP foundation model Llama. The other one is Chronos, from Amazon. In the second part, we give an opinionated view on the challenges of the field.
Foundation models, you say?
A foundation model refers to a deep learning model being trained once on a huge dataset comprising different domains, in the hope that it learns the core concepts (e.g. in NLP, meaning of words and structure of sentences). This is usually done by a large organisation distributing it either open-source or as a paid service. Next, you can apply the model on your own data, while taking advantage of the knowledge transferred from all the samples in the huge dataset. The technique of transferring knowledge to your own task/data is referred to as transfer learning. This idea has been tremendously successful in CV and NLP, one needs to look no further than ChatGPT. To fulfill the requirement of a huge diverse dataset, companies (Google, Amazon, Nixtla …) and researchers have been curating large time series datasets of 100 billion data points. These comprise energy, transport, healthcare, retail, finance … you name it.
Forecasting foundation models in practice
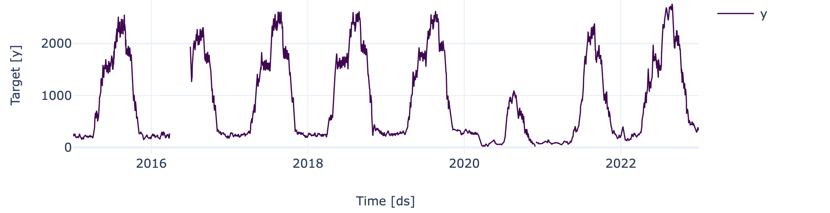
The forecasting foundation models claim their results are competitive or even superior to traditional methods and that they are able to generalize to unseen time series. However, this is in an academic setting. That’s why we wanted to try them out for ourselves in a practical setting. The below graph shows a real-world time series containing daily data. You can notice some data is missing in 2016 and the Covid period resulting in anomalous behavior. Apart from that, the pattern is pretty regular.
 We forecast the last 2 months of 2022 using the three foundation models TimeGPT, Lag-Llama and Chronos. For daily data, this means about 60 timestamps. To compare to a traditional model, we used Prophet. The results are in the graph below where we only show the year 2022.
We forecast the last 2 months of 2022 using the three foundation models TimeGPT, Lag-Llama and Chronos. For daily data, this means about 60 timestamps. To compare to a traditional model, we used Prophet. The results are in the graph below where we only show the year 2022.
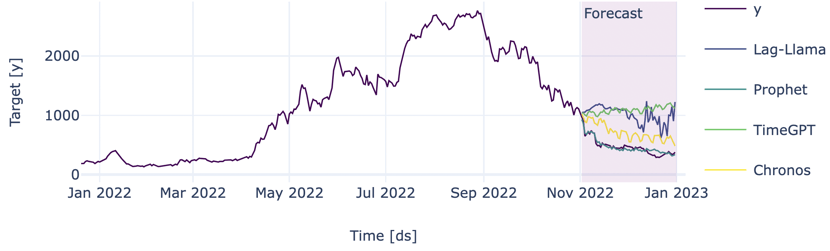 Quite disappointing, let’s dig a bit deeper. Prophet (turquoise) has a good forecast, closely following the actual time series (purple). On the other hand, Lag-Llama and TimeGPT (blue & green) forecast gibberish. Chronos follows the correct downward trend, but it is slightly off. We notice that the foundation models struggle to predict a value for each day. If we instead look at monthly averages like in the graph below, they perform much better. We suspect that this is due to the fact that the foundation models can only look a limited number of steps into the past, so with daily steps, they can't see enough past data to make accurate predictions. Especially Chronos now performs really well, beating the untuned traditional Prophet model. Granted, we could have chosen a better base model that might have outperformed Chronos. However, that is precisely the advantage of the foundation model: it should operate well out of the box on a variety of time series.
Quite disappointing, let’s dig a bit deeper. Prophet (turquoise) has a good forecast, closely following the actual time series (purple). On the other hand, Lag-Llama and TimeGPT (blue & green) forecast gibberish. Chronos follows the correct downward trend, but it is slightly off. We notice that the foundation models struggle to predict a value for each day. If we instead look at monthly averages like in the graph below, they perform much better. We suspect that this is due to the fact that the foundation models can only look a limited number of steps into the past, so with daily steps, they can't see enough past data to make accurate predictions. Especially Chronos now performs really well, beating the untuned traditional Prophet model. Granted, we could have chosen a better base model that might have outperformed Chronos. However, that is precisely the advantage of the foundation model: it should operate well out of the box on a variety of time series.
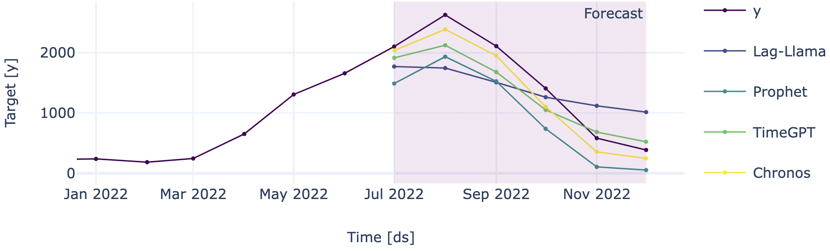 It’s clear from the daily forecast that the foundation models are not fully there yet. As this is a minimal use case, foundation models for forecasting are a no-go in a lot of scenarios where the history exceeds the context window or the forecast goes too far into the future. However, if you want to have a baseline forecast fast without any tuning or your time series is on higher time scales, a foundation model might be worth trying out.
It’s clear from the daily forecast that the foundation models are not fully there yet. As this is a minimal use case, foundation models for forecasting are a no-go in a lot of scenarios where the history exceeds the context window or the forecast goes too far into the future. However, if you want to have a baseline forecast fast without any tuning or your time series is on higher time scales, a foundation model might be worth trying out.
Still, there are some things to keep in mind if you do opt for a foundation model in forecasting:
🔴 They are in the early stages of development, causing a lack of user community and support as a consequence.
🔴 The forecasts are generally slower than in the case of traditional models (on the order of 100 in the case of a single time series).
🔴 Closed-source TimeGPT: cost per token is high. Forecasting the daily time series with all of its history cost 3.6$. Forecasting at a large scale would decrease the cost by ~10 or ~30 times. Open-source models require the associated GPU usage.
🟢 The foundation models are not as compute-intensive as their NLP counterparts (in the order of 1000 times less).
🟢 Applicable out of the box, compared to tuning/experimentation of traditional models.
🟢 No training required yourself.
Identifying challenges in time series foundation models
A foundation model requires shared semantics
As mentioned before, foundation models rely on the concept of transfer learning in order to successfully apply them on your own data. So, for transfer learning to be viable, you first need a clear concept of what to transfer. Or simpler put in the case of forecasting: what do all time series have in common, what semantics do they share? In NLP, it is clear: the meaning of words, how they relate to each other, the structure of particular words in a sentence, typical references to words from previous sentences... Similarly for CV: the objects that are part of our physical world, which objects are often together, typical geometries like bends and lines shaping the object... For time series, this is less straightforward. Some shared structures they possess are holidays, certain trends in society, and global events (e.g. COVID). You can also imagine the ‘foundation’ is more broad within a certain application domain, e.g. bike transportation can increase across countries while this has nothing to do with unemployment rates. Another shared structure is the relationship between past values and how they relate to values in the forecast window. E.g. if the last timestamps are going down, the forecast also probably needs to keep going down.
Forecasting requires context
Apart from the more vague ‘foundation’ in the case of time series, forecasting time series has some additional difficulties to overcome. We will draw a parallel with NLP or CV where possible. For one, you need to be able to forecast for different horizons. The further into the future, the more you’ll likely deviate from reality. We can make a nice comparison with a use-case from CV: outpainting. The time series up until today resembles the image you give, then you ask the model to continue the drawing outside its borders (forecast). Near the border, you have a pretty good estimate of what could come next. Let’s say the image is a garden, then you could continue to draw the grass and some branches of the tree. Further on in the horizon, you can draw multiple plausible things. Maybe a new plant, but you don’t know for sure. To solve this, you should prompt/guide the outpainting model with some text about what objects should be in there. Likewise, a foundation model for forecasting should have the functionality to be ‘prompted’ about what would happen in the future. In forecasting jargon, these are called covariates. For instance, a forecast about ice cream sales involves prompting about what the temperature is going to be. This way, you give the forecasting model clues about which plausible outcomes are the most likely and should be chosen as the forecast.
Currently, foundation models such as TimeGPT only allow for prompts of the type of another time series such as the temperature prediction from the example (Lag-Llama and Chronos aren't even capable of a prompt). They are trained across domains, without the model having any context in regards to this. How valuable would it be if you could prompt your forecasting foundation model with text as well? For example, you could pass the information your time series is in application domain X, causing the model to implicitly filter specific data relations present only in that domain. You could also mention you’re in country Y, causing the model to take those holidays into account and have an idea about the consequences in your domain (think Black Friday). Maybe, you could even go as far as explaining details about the underlying process that produces your time series. If such a large dataset would be created, such a future is not that far-fetched. After all, we’re generating images and music based on text already today.
Forecasting high-frequency data requires long context windows
The ability to learn and forecast different time granularities is another hurdle. Time series could have timestamps every minute, hour, day, month, year etc. Let’s say we have a time series on a minute level and with a yearly pattern, e.g. a maximum in summer and minimum in winter, but still fluctuating from minute to minute. The relevant context for the forecast is one year ago, meaning 60 (minutes per hour) * 24 (hours per day) * 365 (days per year) = 525 600 timestamps ago. This means the model would need a context window of at least the same length. Currently, the context lengths are limited to only on the order of 1000 timestamps. In NLP on the other hand, the context window has already evolved to 128k (notice that it’s still lower than what we need in the example), but at a high compute cost. Even if the context window would be large enough, finding the relevant timestamp out of the 525 600 is like finding a needle in a haystack.
Conclusion
It’s evident that foundation models for time series forecasting are still in their infancy, as seen from our experiment. However, they are displaying promising potential in simpler use cases and are low-effort. We cannot forget these are only the first foundation models being trained, similar to GPT-1 and 2 back in the day. We got some insight into the challenges of forecasting time series with foundation models and saw that incorporating context information might be a future improvement enabler, similar to prompting in NLP. However, for now, we have to stick with the more traditional methods in most use cases, even though they require more tuning to get the job done.

