OpenAI recently released the newest version of their GPT model, GPT-4. This model is a significant upgrade from the already powerful ChatGPT. The impressive ability of GPT-4 to answer complex questions on a wide range of topics has made many headlines. It has memorized an enormous amount of information which it learned from large online text datasets. Beyond memorization, it can even do creative tasks such as coding, copywriting and inventing new recipes. All these skills enable a large set of applications for GPT-4. As Radix is a contributor to the OpenAI evaluation code [1], we have already been granted priority access to the GPT-4 API. This allows us to build new projects that utilize this powerful tool.
How can you best incorporate GPT-4 to increase efficiency? And how can you tailor it to your own data? That is exactly what we want to help you shed light on with this blog post.
Efficient information gathering with GPT-4!
One area where GPT-4 can superpower your company is by providing information. Many organizations, particularly big ones, struggle with employees spending significant amounts of time searching for the information they need to do their jobs. While internal search tools exist, employees often rely on 1-to-1 communication through email or meetings to retrieve information. According to McKinsey, knowledge workers spend 19% of their time trying to find information [2], resulting in wasted time and inefficiency.
However, imagine if GPT-4 learned all the internal information of the organization. Then it would be able to instantly answer any questions of employees directly, providing quick and easy access to information while eliminating the need for employees to search through tons of documents themselves and have endless back-and-forth communication with colleagues!
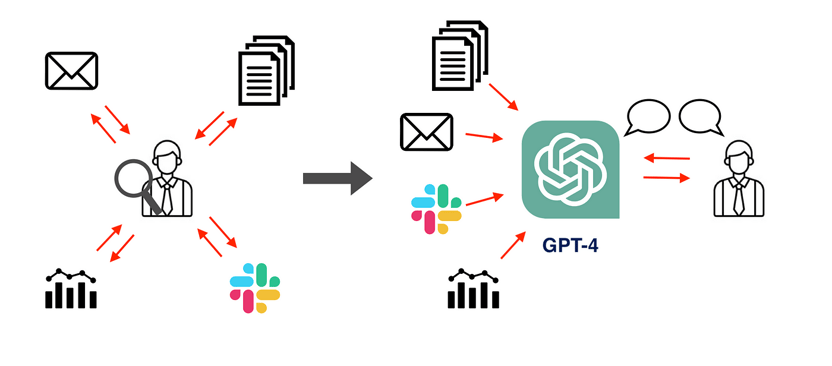
Furthermore, employees regularly create new documents and data that can quickly become lost. You could have GPT-4 read every new document produced so that it would always provide up-to-date information, reducing the need for meetings and emails to stay informed.
Andrej Karpathy, former director of AI at Tesla and now researcher at OpenAI, also sees Large Language Models as the way that we'll interact with information in the future:
An internal perspective
Here at Radix, we have the same challenges. We have worked on a wide variety of interesting Machine Learning problems, but newcomers to the company might not necessarily be aware of the specific details of our past projects and what was learned during these. Usually, it would be necessary for a new member to go around asking others for the needed details, which can be quite a hassle. Luckily, we already have many case studies and blog posts on our website describing past AI problems and solutions that we dealt with in detail. Additionally, we have an internal technical guide to the best Machine Learning and project management practices to be followed within Radix. Therefore it would be great if we could load all this information into GPT-4, making it possible to ask our own AI helper for advice.
But it’s not all sunshine and roses: The limitations of GPT-4
While GPT-4 is an extremely powerful tool, it does have some disadvantages that are related to its training:
- GPT-4 is a large language model that is trained to predict missing words in sentences. It's not designed to be factual, so it may generate answers that sound probable but are entirely made up by the AI.
- GPT-4 doesn't know where the information it has learned comes from, so it can't provide sources for the answers it generates. This makes it difficult for a user to verify the statements it makes.
- Training GPT-4 on your own data is very hard because it uses an approach called Reinforcement Learning from Human Feedback. This requires the model to be trained with human helpers that select good answers by hand, which is then provided as feedback to the AI. This process needs a lot of effort and money.
All these challenges make it hard to use GPT-4 out of the box if you want to apply it to your internal knowledge in a dependable way.
AI Retriever to the rescue
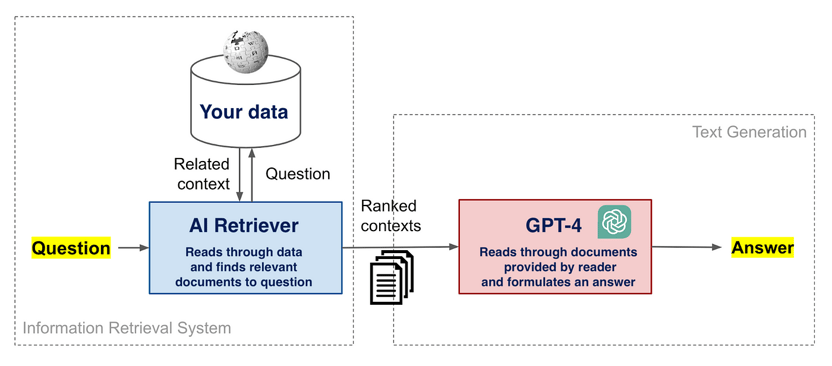 Luckily there exists a simple approach that eliminates all these three challenges in one swoop, called open-book generative question answering. This method adds another AI called the ‘retriever’ (i.e the open book) to help GPT-4. This retriever will search through the organization's documents in order to find the most relevant information needed for answering the question. GPT-4 is then forced to only use the provided information to answer the question, which prevents it from making something up. While answering, GPT-4 can also be forced to reference the source of the information, which then enables the user to easily verify the answer. Finally, this approach requires no further training of GPT-4. In other words, this solution saves a lot of time and effort while providing a better and more useful result.
Luckily there exists a simple approach that eliminates all these three challenges in one swoop, called open-book generative question answering. This method adds another AI called the ‘retriever’ (i.e the open book) to help GPT-4. This retriever will search through the organization's documents in order to find the most relevant information needed for answering the question. GPT-4 is then forced to only use the provided information to answer the question, which prevents it from making something up. While answering, GPT-4 can also be forced to reference the source of the information, which then enables the user to easily verify the answer. Finally, this approach requires no further training of GPT-4. In other words, this solution saves a lot of time and effort while providing a better and more useful result.
Our own Radix GPT-4!
We built a question-answering AI based on the data found on the Radix website as well as the information found in our internal documents. This new tool allows newcomers to ask questions about Radix, with the AI providing concise answers and linking to where the information can be found. It works by having a retriever search through our documents, finding relevant ones and then providing them to GPT-4 to generate an answer. In an upcoming blog post, we will provide all the technical details as to how we built this AI.
One of the most important aspects of building a good question-answering AI is managing to connect it with great search. Without being provided with the right information, even GPT-4 can't answer your questions about internal data. There are several key challenges in doing this:
- Many data types like word documents, SharePoint, PDFs or websites were designed to be read by humans, not computers. These are typically called unstructured data. Good search requires careful thought of the processing of this input data to make it easier for computers to understand.
- Your internal data might use terms and expressions specific to your company that the AI retriever is not familiar with, making it less effective. However, by fine-tuning the retriever to your own data, it can learn these, improving the quality of the search. Such a fine-tuning dataset is easily created using customer data or FAQ documents, which many organizations already have.
In short...
AI has the potential to significantly improve information retrieval for both small and large organizations that are accumulating large amounts of unstructured data. These methods have the potential to eliminate the inefficient and tedious step of acquiring information in 1-to-1 correspondence with other members of the organization. Instead, questions can be formulated to an AI helper that quickly provides the information without the need to search through internal documents. This is today possible with state-of-the-art AI models like GPT-4. However, the key challenge of such an implementation is building a great system for search that works for you. This requires expertise and careful work on the data itself, and it can often be necessary to make a custom AI retriever fine-tuned to your internal knowledge. However, when done right, it can hugely improve efficiency for everyone!
[1] https://github.com/openai/evals
[2] https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/the-social-economy

